


作者:史晓薇1,卫强1,陈国青1
单位:1.清华大学经济管理学院,北京 100084
引用:Xiaowei SHI, Qiang WEI, Guoqing CHEN. A bilateral heterogeneous graph model for interpretable job recommendation considering both reciprocity and competition. Frontiers of Engineering Management, 2024, 11(1): 128‒142 https://doi.org/10.1007/s42524-023-0280-2
文章链接:
https://link.springer.com/article/10.1007/s42524-023-0280-2
https://journal.hep.com.cn/fem/EN/10.1007/s42524-023-0280-2
摘要:在招聘生态系统中传统求职方法效率低下的情况下,自动化职位推荐系统的重要性更为凸显。然而,现有为最大限度地提高用户点击率而优化的模型被证明难以应对职位推荐中的独特挑战,即互惠和竞争。此外,在线招聘平台上的稀疏数据会进一步对现有职位推荐算法的性能产生负面影响。为了抵消这些局限性,我们提出了一种基于双边异构图的竞争选代模型,该模型由三部分组成:1)用于从人员和职位中捕获多源信息并缓解数据稀疏性的两个双边异构图,2)用于综合属性和偏好以产生互惠职位匹配的融合策略,以及3)通过两阶段优化算法实现的分散竞争的竞争增强策略。通过增强可解释性的细粒度注意力机制,该模型的有效性、竞争分散性和可解释性通过在真实世界招聘平台上严格的实验评估得到验证。
关键词:职位推荐;竞争;互惠;可解释
1.
研究背景
尽管猎聘、领英等专业的在线招聘平台发展迅速,为求职者提供了海量的职位信息(Yi et al., 2007),但是浏览数千个职位,经历复杂的筛选和联络过程,以找到少数的匹配职位仍然是一项乏味而复杂的任务。人力资源管理协会SHRM的调查数据显示,求职者锁定一项职位平均大约需要 42 天,在此期间企业在招聘环节将花费 4000 美元。招聘市场中低效的现状迫切需要一种推荐系统,能够快速准确地为求职者展示与其期望相符的职位。
与一般购物网站的推荐系统相比,职位推荐有其自身的特点:互惠和竞争。根据互惠推荐系统(Reciprocal Recommender Systems,RRS)的描述,互惠是指最终用户和被推荐的用户都应该接受“匹配”的推荐(Palomares et al., 2021)。职位推荐作为互惠推荐的典型代表,其中求职者与职位的匹配与求职者是否满足职位的要求相关,同时受到职位的属性和特征是否满足求职者偏好的影响(l-Otaibi and Ykhlef, 2012)。因此,一次成功的互惠职位推荐不仅包含求职者申请偏好的职位,还包含职位的人力资源部门对求职者积极的互动和反馈。
竞争是指与书籍、电影等传统产品可以不受限制地推荐给成百上千的用户不同,职位是一种稀缺的资源,每个职位通常只需要一个或少数几个求职者(Borisyuk et al.,2017)。即求职者在同一职位上存在排他的竞争性,一个职位不能同时满足所有求职者的需求。因此,向多个潜在候选求职者推荐同一份职位会增加竞争,从而降低申请的平均成功率。除了以上两方面的特性,职位推荐还具有更加显著的数据稀疏的特点。这源自在线招聘平台的动态特性,即职位和求职者在满足需求后会离开平台,新求职者的涌入加剧了双方交互数据和标签稀疏的问题(Sorokin and Forsyth, 2008)。
然而,当前职位推荐系统大多以求职者点击概率最大化为目标,较少考虑该领域互惠、竞争和数据稀疏的关键特征(He et al., 2023)。这会导致求职者的投递成功率低下,整体就业市场不平衡,影响招聘和求职效率以及企业人才引进的可持续发展。根据以上对职位推荐特征和研究现状的分析,设计一个高效的职位推荐方法,还面临以下多方面的挑战。
在职位推荐中建模互惠特征的关键在于学习和匹配求职者和职位的双边偏好。这要求模型不仅需要考虑求职者的个性化偏好,还应评估求职者属性与职位需求之间的一致性程度。此外,除了吸引求职者点击外,提升求职者投递岗位的成功比率是影响职位推荐方法中用户满意度的关键因素。因此,基于求职者在职位上竞争排他的特征,如何分散同一职位上求职者之间的竞争压力,向一定数量的求职者推荐同一职位,提升求职者的投递成功率是当前职位推荐中亟待解决的问题。此外,处理稀疏数据的能力决定着职位推荐方法的应用场景和鲁棒性。目前,当前平台用户更加注重个人信息的保密性,在推荐阶段,由于隐私保护机制,诸多场景无法获取求职者简历中工作经历等详细的文本描述信息,推荐系统更多依赖于求职者在平台中披露的结构化特征和行为数据。有限的结构化特征和行为数据进一步增加了解决数据稀疏和标签单一问题的难度。此外,在实践场景中,模型的使用者通常需要模型披露一定的推荐原因提升其对模型的信任和理解。因此,设计具有可解释效果的智能职位推荐模型,辅助求职者快速有效决策,也是当前职位推荐方法面临的挑战之一。
为了应对以上挑战,本研究设计了ReComJob模型,即一个结合互惠和竞争领域特征的基于双边异构图的竞争迭代模型,以实现智能的职位推荐。首先,异构图在整合多源信息、应对稀疏数据任务上具有显著优势,因此本研究根据求职者和职位在平台中披露的结构化属性和点击信息构建与求职者点击和属性相关的异构图以及与职位点击和属性相关的异构图(Shi et al., 2019)。异构图可以用来学习结点之间的信息和连接关系,进而整合以促进对求职者和职位偏好的理解和学习。基于此,我们应用了各种融合策略建模双边匹配并实现互惠的职位推荐。为了利用双边异构图的结构特性和结点信息,我们定义了基于元路径的一阶和二阶邻居结点,通过结点之间的信息连接、传递和整合,可以有效应对数据稀疏性问题(Sun et al., 2011)。此外,异构图中的信息传输可以将标签传播到未被观察到的结点中,其中具有相关性但未被观察到的结点相比于不相关的结点会被赋予更高的概率得分(Zhang et al., 2022)。因此,为了缓解标签(即点击数据)稀疏的问题,本文进一步定义了基于元路径的三阶和四阶邻居结点,通过三阶邻居的信息传播,可以根据相关性为缺失的点击数据添加加权的标签信息。
此外,我们认识到仅基于求职者属性或技能特征评估求职者与职位匹配程度存在局限性。评估求职者与职位匹配程度依赖于职位招聘人员对求职者申请的反馈,例如职位HR 点击求职者的申请(Belavina et al., 2020)。因此,为了评估职位推荐中的双边匹配,我们考虑 HR 点击(表明职位对求职者的正面反馈)而不是求职者点击作为模型学习的目标。职位HR点击包含了更进一步的反馈信息,即同时包含了求职者对职位的偏好(求职者投递点击职位),和职位对求职者的偏好(职位HR点击求职者),从而反映了求职者和职位的互惠偏好。
为了缓解求职者在同一职位上的竞争压力,本研究中引入了一种竞争增强的学习策略,将求职者之间的竞争关系显式化地加入模型的训练过程。该策略包括一个两阶段的学习过程和一个基于求职者在职位上竞争排名和竞争偏好的个性化调整权重。这个权重用于调整初始的HR点击评分,实现对相同职位上求职者竞争热度的分散。求职者的排名与求职者的竞争力呈正相关的关系,即排名越高,竞争力越强,更容易在众多候选人中脱颖而出,获得职位HR的点击。因此,本研究将其作为调整最终职位HR点击得分的一个重要影响因素。将竞争而不是某一职位被投递的数量作为调节权重,是因为求职成功与否更重要的是受到求职者与其他候选人相对优势的影响而非竞争者绝对数量的影响。此外,考虑到竞争可以在不同程度上促进或削弱内在动机(Locke and Latham, 1990),我们将个性化的竞争偏好加入到竞争调整权重中,以分散竞争并潜在增强求职成功率。
异构图有强大的数据表示能力。然而,提取和学习图中结点和结构特征需要应用深度学习方法,如图神经网络(GNNs)(Zhang et al., 2022)。然而,GNNs的复杂性带来了“黑匣子”问题,进而损害了其在实际应用中的可靠性(Ying et al., 2019)。在职位推荐的背景下,需要提高模型的可解释效果以增强求职者对模型可信度和公平性的信心。为了解决这一挑战,本研究在GNN的嵌入式学习过程中设计了不同粒度的注意机制,实现考虑求职者个性化偏好的职位推荐。具体来说,元路径级别的注意权重被用来解释推荐原因,比如基于与先前喜爱职位的地理相似性推荐职位。此外,ReComJob模型在推荐结果中提供了HR点击评分和竞争评分,使求职者进一步理解推荐原因,辅助求职者实现快速决策。
本研究进行了大量实验,使用真实的招聘平台数据,证实了ReComJob相对于基准模型的性能优势。在此基础上设计了案例实验,以说明ReComJob的可解释效果。
总之,我们提出了一种有效的职位推荐模型ReComJob,能够应对领域中互惠匹配、竞争排他性和数据稀疏性的复杂特征。与通常关注精确度和多样性结合的推荐算法不同,ReComJob模型整合了互惠和竞争的领域特征,互惠涉及同时对双方的偏好进行建模和匹配,而不仅仅是将求职者和职位的推荐结果简单结合。此外,我们基于HR点击衡量求职者与职位的匹配,使推荐结果能够吸引求职者的点击,同时职位能够提供积极的反馈。此外,竞争与多样性不同,无法通过多样性的相关设计方法解决。多样性推荐是向个人推荐多个差异化的职位,而分散竞争是减少向不同求职者推荐相同职位的数量。本文中引入竞争特征的目标是通过竞争迭代来最大化求职者的点击量,同时考虑其在职位中的竞争力,从而提高职位HR的点击概率,即提高平均的投递成功率。在本文中,我们引入了竞争调整权重,通过两阶段迭代优化的方式调整初始的HR点击得分。一方面,可以学习个性化的竞争偏好,以实现不同程度的竞争分散。另一方面,可以为求职者提供一个可视化的竞争排名,解释推荐原因,增强推荐结果的可解释效果。
本文的后续部分如下。第2节简要回顾了相关的研究进展。第3节深入探讨了ReComJob模型的技术复杂性,第4节提供了对模型性能的全面评估并讨论了结果的可解释效果。最后,在第5节中进行了总结。
2.
文献综述
2.1 职位推荐
近年来,职位推荐中双边匹配的特性在算法层面得到了优化。通过双边匹配算法,候选人的技能可以满足职位的要求又不会过度浪费(Xu et al., 2016; Lian et al., 2017)。深度神经网络被用于提高求职者和职位的双边匹配程度。例如,Zhu等人(2018)设计了一个卷积神经网络,通过量化候选求职者资质与职位要求的潜在表示之间的距离来评估匹配。Bian等人(2019)针对标签稀疏的问题,提出了一个全局匹配的深度学习模型以捕获职位描述和求职者简历中句子之间的全局语义交互。Sun等人(2019)介绍了一种“双向选择”算法,以帮助职位有效地选择求职者。Qin等人(2020)提出了一个基于话题的技能感知的人岗匹配神经网络方法,以实现对职位和求职者的双边匹配分析。该框架包含两个分层的基于主题的能力感知结构引导语义表示学习,同时结合职位技能要求的全局语义以及候选人的相应经验预测求职者与职位的匹配度。
人力资源领域中,部分研究涉及就业市场中的竞争关系。例如,Collins和Mcnamara(1993)应用博弈论来优化一个停止问题,并探讨竞争对求职策略的影响。Anderson和Burgess(2000)从状态层面上发现内生的职位竞争对匹配函数的影响。Pierrard(2008)研究了个体之间跨区域竞争对国家失业率的影响。以上研究均是探讨宏观层面的竞争关系,并没有深入讨论竞争对个体求职成功的影响。一些心理学和行为学研究表明,竞争可以通过减少或增强人们的自我决定力来减弱或增强参与者的兴趣。这取决于个体对于竞争的感知程度(Deci and Ryan, 1985; Song et al., 2013)。因此,在设计求职推荐算法时,需要纳入求职者的个性化竞争偏好。
在职位推荐的背景下,一些研究强调了竞争排他性的领域特征。职位资源的稀缺性决定了每个职位只能容纳有限数量的个体。因此,与一般商品不同,职位推荐不能只根据求职者的偏好将某一职位推荐给成千上百的求职者(Kenthapadi et al., 2017)。Borisyuk等人(2017)提出了一种管理职位申请数量的调控策略。然而,影响求职者成功的并不是投递的绝对数量,而是求职者在众多竞争对手中的相对排名。因此,通过竞争排名进行优化比控制投递数量更为契合,构成了本研究提出的职位推荐模型的重要设计要素。
2.2 异构信息网络
异构图能够表示不同类型的实体和关系,在现实场景中被广泛应用,包括文献网络、社交媒体网络和知识图谱(Sun et al., 2011)。现有的异构图表示学习倾向利用元路径来管理异构特征的复杂性(Tang et al., 2015; Wang et al., 2016)。例如,Zhao等人(2017)通过在异构图中引入类似于元路径的元图,解决高维信息整合问题。Dong 等人(2017)提出了名为Metapath2vec的异构图表示学习方法,利用元路径引导异构图中的随机游走。Shi等人(2019)提出了名为HERec的异构图表示学习方法,融合不同元路径方案中学习到的特征表示和矩阵分解技术,提升了对异构图的表示学习效果。
除了基于元路径的方法,近年来图神经网络(GNNs)备受关注。GNNs通过使用空间滤波器生成结点的嵌入表示,并通过层传播结构信息(Zhou et al., 2020)。Tu 等人(2018)提出了深度超网络嵌入模型,旨在挖掘异构图中的局部和全局结构。Wang等人(2019)提出了异构图注意力网络,利用分层注意机制学习结点和语义的重要性。后续研究陆续设计了基于注意力机制的异构GNNs(Hong et al., 2020; Hu et al., 2020)。例如,Hu等人(2019)设计了面向短文本分类的异构图注意力网络。结构化的异构图注意力神经网络(HetSANN)(Hong et al., 2020)和异构图转化器(HGT)(Hu et al., 2020)利用单一类型结点作为中心,计算其周围其他类型结点的重要性,为邻居结点分配不同权重。在本研究中,我们利用异构图来解决职位推荐中数据稀疏的挑战,设计了基于领域特征的网络结构和注意力机制,学习求职者的个性化偏好。
3.
双边异构图竞争迭代模型
假设具有一系列的求职者U = [u1, u2...um] 和职位J = [ j1,j2...jn ],其中 m 和 n 分别表示求职者和职位的数量。相应地,T = [(u1, j1), (u2, j1)...(um, jn)] 用于表示求职者集合 U对职位集合J 的投递集合,对应的HR反馈点击集合记为Y = [y1,1,y1,2...ym,n], 其中y∈{0,1},表示 HR 是否认为该求职者匹配本职位,y = 1 表示匹配(即求职者申请了该职位并获得了HR 的点击);y = 0 表示不匹配。
基于上述定义,我们正式提出ReComJob模型,即一种双边异构图竞争迭代模型,旨在缓解研究背景中提出的挑战。该模型利用求职者属性和申请信息构建求职者异构图,并利用职位属性和点击信息构建职位异构图。ReComJob模型包括三个核心组件:异构图的生成和基于元路径的邻居结点生成,注意力增强的异构图表示学习,以及基于双边匹配和竞争迭代的职位推荐。图1展示了ReComJob的整体架构。

图1. 双边异构图竞争迭代模型
3.1 异构图的生成和基于元路径的邻居结点生成
首先,为了基于当前隐私保护背景下有限披露的数据特征学习求职者和职位的属性和偏好,建模职位推荐中的互惠特征,本研究整合求职过程中的各类属性和点击信息,分别构建基于求职者点击和属性的异构图以及基于职位HR点击和属性的异构图。
异构图中的结点包括求职者结点、求职者属性结点、职位结点和职位属性结点。结点的连接包含四种关系:求职者具有求职者属性,职位具有职位属性,求职者点击职位,职位HR点击求职者。在属性结点方面,本研究借鉴先前在职位推荐领域的研究,确定了公司规模、类型、地区、工资、求职者职能、年龄和教育水平作为关键的属性结点,如表1所示。本研究基于领域知识筛选异构图结点,一定程度上可以控制异构图中元路径的数量和有效性,提升算法效率(Epasto and Perozzi, 2019)。
表1. 属性汇总表

利用元路径可以区分不同属性或偏好路径对最终匹配的贡献,解释推荐结果(Yang et al.,2023)。对于求职者点击图,异构邻居结点可以通过基于元路径的一阶连接获得。比如求职者点击的职位记为“求职者-职位”。对于职位HR点击图,基于元路径的一阶连接同样可以获得异构的邻居结点。此外,利用基于元路径的二阶连接可以获取同质的邻居结点,例如“求职者-职位-求职者”可以表示具有共同点击关系的求职者,得到基于点击相似性的求职者之间的关系。此外,我们引入了更深层次的基于连接的信息传递机制,包括基于元路径的三阶和四阶邻居结点。这些结点可以建立稀疏数据之间基于相似性的潜在点击关系,为新的求职者或职位添加潜在的点击标签。这些更深层次的连接不仅解决了稀疏性问题,还有效解决了标签不平衡的问题。研究中进一步在两个异构图中分别生成针对求职者和职位结点的基于元路径的三阶、四阶异构和同构邻居结点,示例如表2 所示。
表2. 基于元路径的三阶、四阶邻居结点示例

边的权重方面,对于每个职位或求职者和属性结点之间的边,边权重设置为1。对于其他边类型,边权重设置为对应的交互或点击的次数。为了区分直接相连的邻居结点和基于传递的潜在邻居结点,即一阶或二、三、四阶邻居结点。本研究使用 n 阶邻居结点的传输次数 n 的倒数作为连接权重,即n 阶邻居结点之间的连接权重为 1/n。
3.2 注意力增强的异构图嵌入表示
为了有效学习求职者的求职偏好,ReComJob模型设计了多粒度注意机制进行异构图的表示学习。利用结点级别的注意力机制来学习每条元路径下的邻居权重并将其聚合以获得特定语义的结点嵌入表示。使用路径级别的注意力机制,学习不同元路径对于最终匹配的重要性,捕获求职者和职位在元路径水平下的个性化偏好。路径级别的注意力机制可以在一定程度上解释推荐结果,从而增强求职者对模型推荐结果的信任和理解。异构图的表示学习过程如图2所示。

图2. 注意力增强的异构图表示学习
在异构图G = {V, R}中,结点和连接的类型集合分别为 Ω 和 ε,V表示结点,R表示连接。对于类型为 τ ∈ Ω 的结点集合 Vτ ,结点的表示矩阵记为Xτ ∈ R|Vτ|*qτ ,其中 qτ表示维度。对于结点 i∈Vτ ,其对应的表示向量是Xτ的第i行。根据Banach的不动点定理(Oltra and Valero, 2004),对在任意初始点 x0 下,柯西序列f(x0)都会收敛到一个固定值。因此,本研究简单地使用结点度的独热编码作为结点的初始特征向量,这在性能方面被相关研究证明是有益的(Errica et al., 2019)。为了使不同类型的结点特征具有可比性,我们采用类型特定的转换矩阵,记为Mτ ,将不同的结点特征投影到统一的维度空间。映射过程如公式(1)所示。

在异构图中,结点 Ω1 和 Ωl+1间的元路径表示为Ω1→(ε1)→Ω2→(ε2)...→(εl)→Ωl+1,其中 Ωl 是结点类型,εl是连接类型。在此基础上,根据元路径的类型可以将异构图划分为多个同构的信息子图,获得子图中基于元路径 Φ 的邻居结点。本研究在信息子图内部设计了一个图注意力层,以根据每个同构图的邻接关系来推导学习结点的潜在嵌入表示。具体来说,针对结点 i ,本研究利用公式(2)学习元路径 Φ 下结点之间的重要性关系,并对所有结点的注意力得分进行归一化,获得结点级别的注意力权重。其中 σ 表示激活函数,|| 表示连接操作,βΦ 是元路径 Φ 下的结点水平的注意力向量。因此,元路径 Φ 下结点 i 的嵌入表示可以通过整合邻居结点对应的注意力系数和映射特征得到,如公式(3)所示。其中 hjΦ 是结点 j 在元路径 Φ 中的嵌入表示学习向量。为了表述的清晰性,后文省略了所有和层相关的层索引标志。

为了对各个元路径的信息进行整合,以可解释的方式学习元路径对最终向量表示的影响,本研究设计了元路径级别的注意力机制区分求职者和职位的偏好,元路径 Φ 的注意力权重记为 γΦ,计算方式如公式(4)所示。其中 c 是元路径水平的注意力向量,VΦ 表示元路径 Φ 下的结点,W 和 b 分别表示权重矩阵和偏置向量。通过使用学习到的注意力权重 γΦ 作为系数,可以整合结点表示以获得结点路径级别的表示学习结果,如公式(5)所示,其中 p 表示元路径的数量。得到的最新表示 E 作为下一层的输入向量。

3.3 基于双边匹配和竞争迭代的职位推荐
经过图注意力表示学习的最后一层可以分别获得求职者点击异构图和职位HR点击异构图中的求职者向量表示和职位向量表示,分别记作 euμ ,eiμ 和 euf,eif。随后,为了建模职位向量和求职者向量表示之间的连接,本研究采用点积和单层感知器来学习求职者对职位的偏好矩阵 K 和职位对求职者的偏好矩阵 F,如公式(6)-(7)所示。

为了建模职位与求职者的互惠匹配程度,需要使用不同的融合策略将求职者点击异构图和职位HR点击异构图得到的交互信息进行整合,记作Γ(K,F) 。在Γ(K,F)互惠推荐中常用的融合策略包括调和平均、算术平均和交叉比函数(Neve and Palomares, 2019a; 2019b)。这三种策略各有优势,适用于不同的问题场景。因此本研究中将上述三种方法分别用于融合计算,得到基于双边匹配程度的推荐得分y ̂u,j ,如公式(8)-(10)所示。在数据实验中对三种方法的结果进行比较,获得最佳的互惠匹配推荐。损失函数采用最广泛使用的平方损失函数度量预测匹配程度 y ̂u,j 和真实匹配程度,即HR 点击得分 yu,j 之间的差异,如公式(11)所示。

基于以上设计完成了模型基于互惠特征的初始匹配预测,在此基础上,本研究加入基于个性化竞争权重的迭代优化模块。引入个性化竞争调整权重的原因在于求职者在职位上竞争的固有排他性以及相对排名对个人被HR赏识和录用产生的重大影响。相关研究证明,根据对竞争偏好的不同,求职者会产生不同方向的内在动机,如增加或削弱动机(Song et al., 2013)。因此,将竞争排名和偏好等个性化因素整合到优化过程中以增强最终匹配得分变得至关重要。
对于每个职位,利用所有求职者的初始匹配分数 y ̂u,j 进行排序,得到初始排名。通过数据,可以得到职位HR点击得分与竞争排名的关系图。如图3所示,可以发现排名与职位HR点击之间存在普遍的负相关关系。

图3. HR点击得分和求职者竞争排名关系图
因此,本研究中设计的求职者的个性化竞争权重 ωu,j 会受到求职者 u 在所有职位 j 的候选求职者中相对排名的影响。排名值越小,在竞争中的相对名次越高,越容易在竞争中获胜。此外,值得注意的是,竞争调整权重还受到个体对竞争偏好的影响。不同的求职者在面对同一竞争水平时,会引发不同程度的响应动机(Song et al., 2013)。因此,个性化竞争调整权重需要衡量每个求职者的竞争排名和因竞争引起的偏好变化,如公式(12)所示。

其中 αu代表求职者 u 对竞争的个性化偏好, Tj表示求职者对职位 j 的投递点击的集合,|Tj| 表示投递职位 j 的求职者的数量。
在训练过程中,该问题可以视为一个两阶段问题,对个性化竞争权重 ωu,j 和初始匹配分数 y ̂u,j 进行迭代,当次 y ̂u,j 使用最近一次的相对排名信息进行调整,当 y ̂u,j的相对大小不变时,相对排名稳定到定值,结果收敛,得到模型的各个参数。最终目标函数如公式(13)所示。

在测试阶段,根据排名和预测的匹配分数得到最终推荐得分,并为每个求职者推荐综合匹配分数较高的职位,实现分散求职者在职位上的竞争热度,提升平均投递成功率的目标。
4.
实验
4.1 实验设置
本研究在中国大型在线招聘平台之一,记作S,获取真实数据集,对模型进行广泛评估。该数据集包括22552个职位和176069名求职者,共计357832条申请记录。为了保护求职者隐私,所有记录均经过去除识别信息的匿名处理。对数据中的HR点击模式进行分析可以发现每个职位的申请数与HR点击数比率的平均值为0.448。这一观察结果表明在求职过程中存在大量的无效申请,显示了考虑互惠和竞争特征以增强效率的重要性。
预处理后的数据被分为三个子集:训练集、验证集和测试集。训练集和验证集用于训练模型参数,测试集用于评估模型性能并根据元路径信息解释推荐结果。
本研究的比较分析涵盖了两个方面。第一部分关注职位推荐模型,包括传统的矩阵分解(MF)模型(Lee and Seung, 2000),以及目前具有较好表现效果的职位推荐算法PJFNN(Zhu et al., 2018)和MUFFIN(He et al., 2023)。第二部分关注与图处理模型的比较,包括DeepWalk(Perozzi et al., 20144)、Metapath2vec(Dong et al., 2017)以及当前较优秀的异构图处理方法HERec(Shi et al., 2019)和HGCN(Yang et al., 2023)。评估指标包括准确率、精确度、召回率和F1值。鉴于本研究中测量的匹配度为0至1之间的连续值,本研究在在评估中加入均方误差(MSE)和平均绝对误差(MAE)。
在接下来的四小节中,我们将在真实招聘数据集上进行大量实验并进行结果分析,以解决以下问题:
Q1: 与其他最先进模型相比,本研究提出的ReComJob模型表现如何?
Q2: 基于竞争的迭代优化模块是否成功实现了在职位推荐中分散竞争的目标?
Q3: ReComJob模型是否有效利用双边异构图模型解决了数据稀疏性问题?
Q4: ReComJob模型如何生成可解释的职位推荐结果?
4.2 模型效果实验
表3显示了模型在各个评价指标上的表现效果。首先,本研究提出的ReComJob模型在所有评估指标上均表现出明显优势。具体而言,交叉率融合策略在F1,准确率,召回率指标上优于其他两种融合策略。算术平均值在均方误差和准确率方面表现最佳,而调和平均值在平均绝对误差方面优于其他两种融合策略。
表3. 职位推荐模型效果对比

其次,在职位推荐模型中,仅关注求职者和职位点击特征的MF模型在互惠匹配上表现不佳。而基于神经网络考虑求职者与职位之间双边特征匹配的PJFNN和MUFFIN在准确性方面取得显著改进。
第三,在图处理模型中,DeepWalk加入了职位和求职者的属性结点,但是没有考虑结点的异构性,受数据学习中的噪声影响导致表现不佳。Metapath2vec考虑结点的异构性,但对图内部结点关系的粗糙处理导致结果并不理想。HERec进一步优化了Metapath2vec中对不同元路径的整合方法,因此准确性相比于Metapath2vec提升约4%。HGCN结合了对象级的聚合和路径级的聚合,从所有可能的元路径中为每个对象提取有价值的信息,因此获得了这类对比方法中最优的表现效果,准确率为0.844。然而,这一准确率仍低于本研究提出的ReComJob模型。
第四,ReComJob考虑基于多阶元路径的邻居结点提供的信息,并考虑了结点和求职者对不同路径的偏好权重,通过设计个性化竞争权重显著提高了模型的学习效果。相比于表现最佳的职位推荐模型MUFFIN,准确性提升2%。相比于表现最佳的图处理方法,准确性提升约4%。
最终,为了评估考虑互惠和竞争的职位推荐模型在求职者点击率(CTR)上的表现效果,我们根据ReComJob以及对比方法的推荐结果计算了CTR指标,如表3最后一列所示。值得注意的是,由于职位HR点击包含了求职者和职位双边的偏好信息,以最大化HR点击为目标的学习不会影响求职者的CTR得分。因此,ReComJob模型能有效提升求职体验,在提升平均投递成功率的同时保持了令人满意的点击率。
超参数对模型性能的影响。其中超参数 Ψ 控制图中的层数,超参数 q 确定结点的表示维度。我们评估了 Ψ 从1到6范围变化以及 q 在{4, 8, 16, 32, 64, 128} 范围变化下的模型性能,如图4所示。我们可以看到,不同参数设置下模型的性能基本保持稳定,表现出良好的鲁棒性,当 Ψ=2, q=16 时,模型的表现效果最佳。

图4. 超参数变化图
消融实验。为了评估模型中各个模块设计的必要性及其对最终效果的影响,本研究进行了消融实验,结果如表4所示。
表4. 模型中不同模块的影响

首先,当去除竞争迭代模块(即ReComJob-competition)时,模型的准确率略微下降约2%。竞争模块旨在分散竞争热度并使推荐多样化,虽然对匹配准确性影响较小,但其存在对模型有积极贡献。
其次,去除基于元路径的三/四阶邻居结点(即ReComJob-third/fourth order neighbors)导致会导致模型准确率显著下降。这突显了纳入基于元路径第三/四阶邻居结点的重要性,即有助于长距离信息的学习和潜在标签的传播,并解决了数据和标签稀疏的问题,提高了模型的准确性。
第三,通过移除基于元路径的二阶邻居结点(即ReComJob-second order neighbors),观察到准确率明显下降。召回率和准确性分别下降约6%和4%。这表明基于元路径的二阶邻居通过学习较为直接的同构结点关系,如投递相同职位的求职者之间的关系,可以有效实现异构图的信息传递,提升职位推荐的准确性。
最后,通过去除结点级别的注意力机制(即word attention)和元路径级别注意力(即metapath attention)仅使用单层感知机连接向量,确认了多粒度注意机制的必要性。去除结点级别注意力机制导致模型准确率下降约4%,强调了结点级别注意力机制在整合结点信息、学习求职者和职位的特征表示方面的有效性。此外,去除元路径级别注意力导致准确率下降约2%,强调了学习求职者个性化偏好的重要性。
4.3 竞争热度分散分析
为了比较竞争迭代优化的职位推荐方法和以最大化用户点击为目标的方法在分散竞争热度方面的效果。我们令两种模型均向同一子组的求职者推荐职位,其职位推荐结果的分布如图5所示。
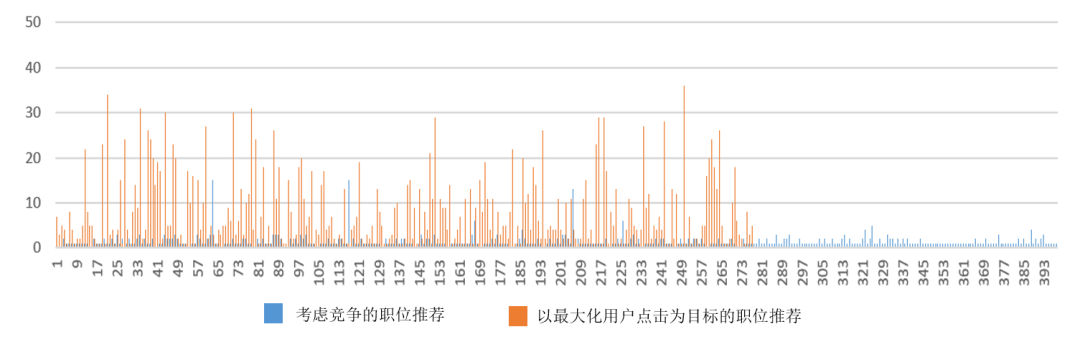
图5. 职位推荐热度对比图
实施竞争迭代优化模型的推荐结果呈现出分散和均匀的特点,表现为单个职位的推荐频率较低且覆盖范围较广。相反,以最大化用户点击为目标的职位推荐结果中职位列表更为集中,呈现出较高的频率和较窄的覆盖范围。
通过比较分析可以明显发现竞争迭代优化的职位推荐方法可以在保证推荐准确率的同时分散职位被推荐的热度,为不同的求职者推荐更符合个人需求的职位。使职位推荐在满足求职者偏好的同时,降低竞争带来的失败风险,提升投递的平均成功率。
4.4 稀疏数据背景下的鲁棒性分析
为了展示模型在处理稀疏数据上的稳健性,我们在不同数据稀疏程度下将ReComJob模型与MF模型和MUFFIN模型进行对比。其中,MUFFIN模型在比较中表现出卓越的性能。本研究沿用Hu等人(2018)的验证方法,将整个数据集分为五个相等部分,逐渐增加训练数据量从一份到四分,对应于20%、40%、60%、80%的数据作为训练集。
图6展示了ReComJob模型在不同训练数据比例下准确性的稳定性。纵轴表示准确性,横轴表示不同训练集比例。值得注意的是,传统MF模型在训练数据比例减少时准确率下降较为显著,表明数据稀疏性加剧对模型学习性能造成了显著影响。另一方面,MUFFIN模型整合多领域特征和点击数据以获取潜在偏好,与MF模型相比表现出相高的稳定性。只有当数据稀疏程度达到临界阈值(训练数据低于40%)时,MUFFIN的准确性才会出现明显下降。这些对比实验证明了异构图模型在整合多种类型信息方面的有效性,展示了其通过结点之间的信息传递有效缓解职位推荐中的数据稀疏问题的能力。

图6. 准确性随训练集比重变化图
4.5 可解释的案例分析
本研究提出的职位推荐模型具有根据求职者潜在职业偏好提供个性化职位推荐的能力。推荐结果可以通过在最终层中利用元路径注意力来解释,从而增强求职者对推荐系统的信任和理解,提升求职和招聘效率。图7阐明了求职者对相似规模,相似职位类型,相似薪水,相似城市的职位基于元路径的注意力偏好权重。大多数求职者倾向于优先考虑职位类型和薪资,这需要成为职位推荐关注的重点特征。虽然一些求职者可能偏好位于相似城市的职位,但公司规模的影响似乎对他们的决策影响较小。求职者偏好的差异也进一步突出了职位推荐过程中引入个性化偏好的重要性。
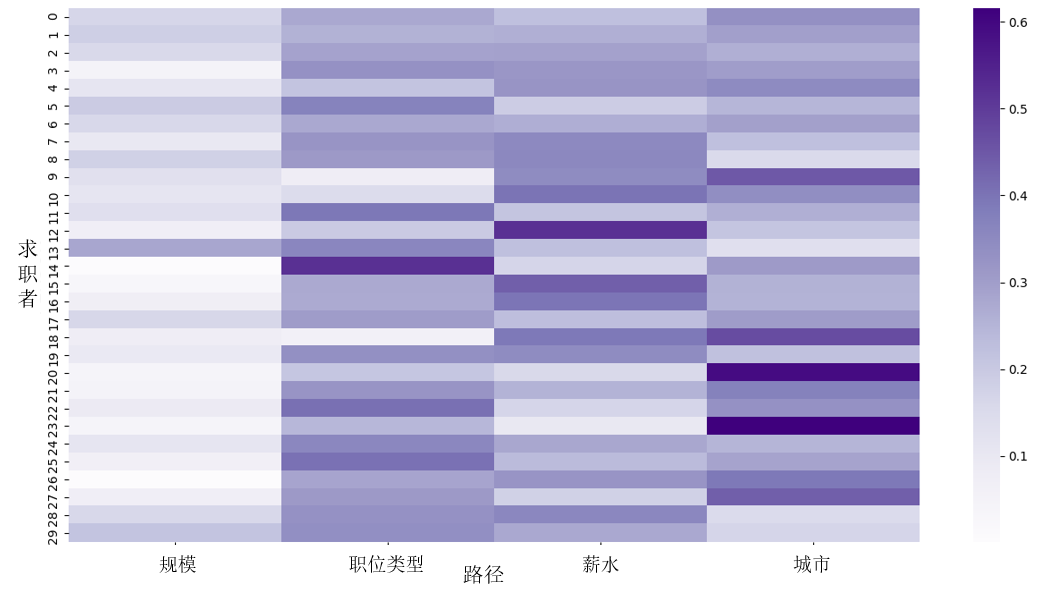
图7. 求职者偏好路径图
表5展示了ReComJob对推荐示例基于元路径权重的解释。此外,与排名相关的竞争调整权重在ReComJob中有显式化的设计。可以发现该求职者对公司规模有较强偏好,并且城市的相似程度也是其着重关注的因素,可以作为推荐的重点。本研究显式化地设计了竞争调整权重,在推荐过程中,在提供基于元路径注意力权重的推荐原因的同时,可以展示竞争排名。显式化的设计方法可以帮助个体理解推荐的详细信息,提升其对推荐结果和投递结果的理解和信心。
表5. 职位推荐样例

5.
总结
本研究提出了一种创新的职位推荐方法,采用双边异构图竞争迭代模型,考虑了互惠和竞争的领域特征。该模型利用异构图和融合机制获取初始推荐得分以满足互惠的双边匹配。此外,我们提出了一个两阶段的迭代优化模块,考虑了个体的竞争排名和竞争偏好,实现对竞争压力的分散。这使得模型能够推荐绝对匹配得分和相对排名均具有优势的职位,从而提高求职的平均投递成功率。基于元路径的注意机制和显式化优化的竞争排名,使得该模型能够识别并适应每个求职者的个性化偏好,同时阐明其推荐背后的原因。
本研究定位于设计科学的研究范畴(Gregor and Hevner, 2013),有效地应对了竞争激烈的双边求职市场中固有的稀疏数据、竞争和低匹配成功率带来的挑战。在实践方面,本研究提供了一个高效的职位推荐模型,可以有效提升求职者的平均投递成功率,加快了求职过程。在方法论方面,本研究提出的包含竞争迭代的异构图模型可以进一步扩展应用于更广泛的双边市场推荐问题。然而,本研究主要关注双边市场中的单边主体(即求职者)。在未来的研究中,基于更广泛的数据集,可以进一步深入探讨满足求职者和职位偏好的双边推荐。




